Reading Rates (See Problem 22 in Section 10.3.) Michael Sullivan, son of the author, decided to enroll in a reading course that allegedly increases reading speed and comprehension. Prior to enrolling in the course, Michael read 198 words per minute (wpm). The following data represent the words per minute read for 10 different passages after the course. c. Generate 5000 independent bootstrap samples of size n=10 with replacement. For each bootstrap sample, determine the sample mean. That is, build a null model.
Verified step by step guidance
1
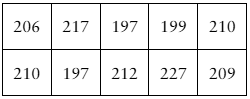
Identify the original sample data, which consists of the words per minute (wpm) read for 10 passages after the course: 206, 217, 197, 199, 210, 210, 197, 212, 227, and 209.
Understand that a bootstrap sample is created by randomly selecting observations from the original sample with replacement, meaning each value can be chosen multiple times or not at all in a single bootstrap sample.
Generate 5000 independent bootstrap samples, each of size n = 10, by repeatedly sampling with replacement from the original 10 data points.
For each of these 5000 bootstrap samples, calculate the sample mean by summing the 10 values in the bootstrap sample and dividing by 10. The formula for the sample mean is:
\[\text{mean} = \frac{1}{n} \sum_{i=1}^{n} x_i\]
where \(x_i\) are the values in the bootstrap sample.
Collect all 5000 sample means to form the bootstrap distribution of the sample mean, which serves as the null model to understand the variability of the sample mean under the assumption that the original sample is representative of the population.
Verified video answer for a similar problem:
This video solution was recommended by our tutors as helpful for the problem above
Video duration:
2m
Play a video:
0 Comments
Key Concepts
Here are the essential concepts you must grasp in order to answer the question correctly.
Bootstrap Sampling
Bootstrap sampling is a resampling technique used to estimate the sampling distribution of a statistic by repeatedly drawing samples with replacement from the observed data. It allows for assessing variability and constructing confidence intervals without relying on strict parametric assumptions.
The sample mean is the average value of a set of observations and serves as an estimate of the population mean. In bootstrap methods, calculating the sample mean for each resampled dataset helps approximate the distribution of the mean under the null model.
A null model represents the assumption that there is no effect or difference, serving as a baseline for comparison. Generating bootstrap samples under the null model helps evaluate the variability of the statistic if the null hypothesis were true.

 Verified step by step guidance
Verified step by step guidance
 05:11
05:11
