

 06:34
06:34
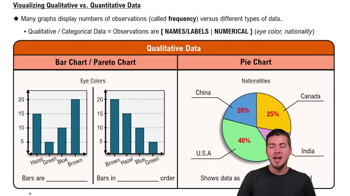

Textbook Question
HIC Measurements Listed below are head injury criterion (HIC) measurements from crash tests of small, midsize, large, and SUV vehicles. In using the Kruskal-Wallis test, we must rank all of the data combined, and then we must find the sum of the ranks for each sample. Find the sum of the ranks for each of the four samples.
141
views