
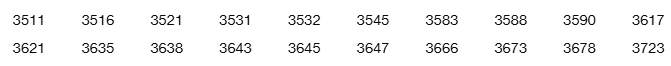

 04:39
04:39
Textbook Question
z Scores. In Exercises 5–8, express all z scores with two decimal places.
Diastolic Blood Pressure of Females For the diastolic blood pressure measurements of females listed in Data Set 1 “Body Data” in Appendix B, the highest measurement is 98 mm Hg. The 147 diastolic blood pressure measurements of females have a mean of 70.2 mm Hg and a standard deviation of 11.2 mm Hg.
c. Convert the highest diastolic blood pressure to a z score.
140
views