 Back
BackChi-Square Tests, Simpson’s Paradox, and Assessing Prediction Accuracy
Study Guide - Smart Notes
 Tailored notes based on your materials, expanded with key definitions, examples, and context.
Tailored notes based on your materials, expanded with key definitions, examples, and context.
Chi-Square Tests & Goodness of Fit
Overview of the Chi-Square Test
The Chi-square test is a statistical method used to determine if there is a significant association between categorical variables. It is commonly applied to contingency tables to test hypotheses about relationships between variables such as survival rates and passenger class.
Null Hypothesis (H0): No association exists between the variables.
Alternative Hypothesis (Ha): An association exists between the variables.
Test Statistic: The Chi-square statistic is calculated as: where O is the observed frequency and E is the expected frequency.
Critical Value: Compare the calculated statistic to the critical value from the Chi-square distribution table at the chosen significance level (e.g., 5%).

Titanic Example: Association Between Passenger Class and Survival
The Titanic dataset is used to test whether passenger class affected survival rates.
Observed and expected frequencies are calculated for each class and survival outcome.
Chi-square statistic is computed and compared to the critical value.
Result: The null hypothesis is rejected, indicating a strong association between passenger class and survival.
Observed Frequencies Table
Passenger class | First | Second | Third | Total |
|---|---|---|---|---|
Survival: no | 80 | 97 | 372 | 549 |
Survival: yes | 136 | 87 | 119 | 342 |
Total | 216 | 184 | 491 | 891 |
Expected Frequencies Table
Passenger class | First | Second | Third |
|---|---|---|---|
Survival: no | 133 | 113 | 302 |
Survival: yes | 82 | 70 | 188 |
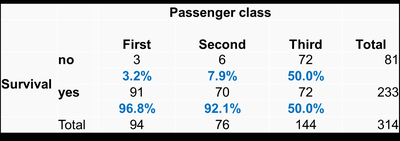
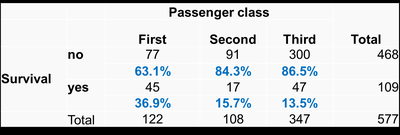
Effect of Gender on Survival
Survival rates are further analyzed by gender and passenger class.
Female Passengers: Higher survival rates across all classes.
Male Passengers: Lower survival rates, especially in third class.
Assumptions of the Chi-Square Test
For the Chi-square test to be valid:
No more than 20% of the cells should have expected frequencies less than 5.
If this condition is violated, categories may be combined to reduce the table size.
Example: Social and Economic Status for Married Couples
Husband's social class | Higher prof | Lower prof | Routine non-manual | Skilled manual | Semi-skilled manual | Unskilled manual | Total |
|---|---|---|---|---|---|---|---|
Wife's Higher prof | 0 | 2 | 0 | 0 | 0 | 0 | 2 |
Wife's Lower prof | 1 | 8 | 5 | 3 | 2 | 1 | 20 |
Wife's Routine non-manual | 4 | 13 | 9 | 15 | 6 | 0 | 47 |
Wife's Skilled manual | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
Wife's Semi-skilled manual | 2 | 5 | 5 | 13 | 8 | 3 | 36 |
Wife's Unskilled manual | 0 | 0 | 2 | 4 | 3 | 0 | 9 |
Total | 7 | 29 | 21 | 35 | 19 | 4 | 115 |
Grouped Table (for valid test)
Husband's social class (grouped) | Professional | Skilled | Semi/unskilled | Total |
|---|---|---|---|---|
Wife's Professional | 11 | 8 | 3 | 22 |
Wife's Skilled | 18 | 24 | 6 | 48 |
Wife's Semi/unskilled | 7 | 24 | 14 | 45 |
Total | 36 | 56 | 23 | 115 |
Simpson’s Paradox
Definition and Example
Simpson’s Paradox occurs when a trend appears in several groups of data but disappears or reverses when the groups are combined. This paradox highlights the importance of considering confounding variables before drawing conclusions.
Example: University of Berkeley admissions data initially suggested gender discrimination, but further analysis showed that females applied more to departments with lower admission rates.
Another example: A study on heart disease and smoking showed higher survival rates for smokers, but confounding factors may explain this counter-intuitive result.
Berkeley Admissions Table
Department | Males Admitted | Males Refused | % Admitted | Females Admitted | Females Refused | % Admitted |
|---|---|---|---|---|---|---|
A | 511 | 314 | 61.9 | 88 | 20 | 81.5 |
B | 353 | 207 | 63.0 | 17 | 8 | 68.0 |
C | 120 | 205 | 36.9 | 201 | 392 | 33.9 |
D | 137 | 280 | 32.9 | 131 | 244 | 34.9 |
E | 53 | 138 | 27.7 | 94 | 299 | 23.9 |
F | 16 | 256 | 5.9 | 24 | 317 | 7.0 |
Assessing the Accuracy of Prediction Results
Confusion Matrix and Performance Metrics
In predictive modeling, accuracy is assessed using a confusion matrix, which compares predicted and actual outcomes.
True Positive (TP): Correctly predicted positive cases
True Negative (TN): Correctly predicted negative cases
False Positive (FP): Incorrectly predicted positive cases
False Negative (FN): Incorrectly predicted negative cases
Example: Fraud Detection
Fraud | Not Fraud | Total | |
|---|---|---|---|
Predicted Fraud | 9000 | 88000 | 97000 |
Predicted Not Fraud | 1000 | 352000 | 353000 |
Total | 10000 | 440000 | 450000 |
Sensitivity (True Positive Rate):
Specificity (True Negative Rate):
Positive Predictive Value:
Example: Diagnostic Accuracy
Illness: Yes | Illness: No | Total | |
|---|---|---|---|
Test Positive | 15 | 95 | 110 |
Test Negative | 5 | 885 | 890 |
Total | 20 | 980 | 1000 |
Sensitivity:
Specificity:
Positive Predictive Value:
Summary
Validity of Chi-square Test: Requires sufficient sample size and expected frequencies.
Simpson’s Paradox: Associations must be interpreted with caution, considering confounding variables.
Prediction Accuracy: Evaluated using sensitivity, specificity, and positive predictive value from confusion matrices.
