In Exercises 21 and 22, (a) identify the claim and state H₀ and Hₐ, (b) find the critical value and identify the rejection region, (c) find the test statistic F, (d) decide whether to reject or fail to reject the null hypothesis, and (e) interpret the decision in the context of the original claim. Assume the samples are random and independent, the populations are normally distributed, and the population variances are equal.
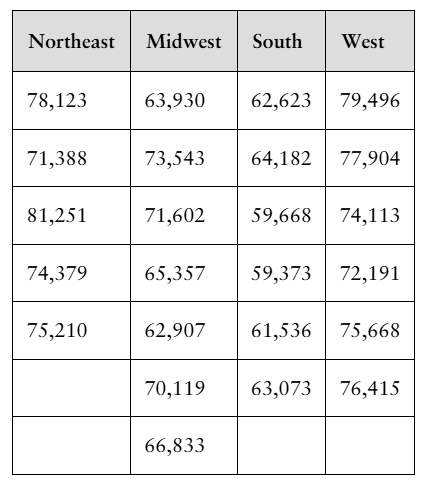
[APPLET] The table shows the annual incomes (in dollars) for a sample of families from four regions of the United States. At α=0.05, can you conclude that the mean annual income of families is different in at least one of the regions? (Adapted from U.S. Census Bureau)
Verified step by step guidance
1
Step 1: Identify the claim and state the null hypothesis (H₀) and the alternative hypothesis (Hₐ). The claim is that the mean annual income of families is different in at least one of the regions. H₀: μ₁ = μ₂ = μ₃ = μ₄ (the mean incomes are equal across all regions). Hₐ: At least one mean income is different.
Step 2: Determine the critical value and rejection region. Since this is an ANOVA test, use the F-distribution table to find the critical value for α = 0.05, given the degrees of freedom for the numerator (k - 1, where k is the number of groups) and the denominator (N - k, where N is the total number of observations). The rejection region is F > critical value.
Step 3: Calculate the test statistic F. First, compute the group means and the overall mean. Then, calculate the sum of squares between groups (SSB) and the sum of squares within groups (SSW). Use these to find the mean square between groups (MSB = SSB / df_between) and the mean square within groups (MSW = SSW / df_within). Finally, compute F = MSB / MSW.
Step 4: Compare the test statistic F to the critical value. If F > critical value, reject the null hypothesis; otherwise, fail to reject the null hypothesis.
Step 5: Interpret the decision in the context of the original claim. If the null hypothesis is rejected, conclude that there is sufficient evidence to support the claim that the mean annual income of families is different in at least one region. If the null hypothesis is not rejected, conclude that there is insufficient evidence to support the claim.
Verified video answer for a similar problem:
This video solution was recommended by our tutors as helpful for the problem above
Video duration:
7m
Play a video:
0 Comments
Key Concepts
Here are the essential concepts you must grasp in order to answer the question correctly.
Hypothesis Testing
Hypothesis testing is a statistical method used to make decisions about a population based on sample data. It involves formulating two competing hypotheses: the null hypothesis (H₀), which states there is no effect or difference, and the alternative hypothesis (Hₐ), which suggests there is an effect or difference. The goal is to determine whether there is enough evidence to reject H₀ in favor of Hₐ.
ANOVA is a statistical technique used to compare the means of three or more groups to determine if at least one group mean is significantly different from the others. It assesses the impact of one or more factors by comparing the variance within groups to the variance between groups. In this context, it helps to evaluate if the mean annual incomes differ across the four regions.
The critical value is a threshold that determines the boundary for rejecting the null hypothesis in hypothesis testing. It is derived from the significance level (α), which indicates the probability of making a Type I error. The rejection region is the range of values for the test statistic that leads to rejecting H₀; if the calculated test statistic falls within this region, the null hypothesis is rejected.

 Verified step by step guidance
Verified step by step guidance
 06:21
06:21
